《Learning Spatio-Temporal Transformer for Visual Tracking》论文阅读笔记
 xfarawayx
xfarawayx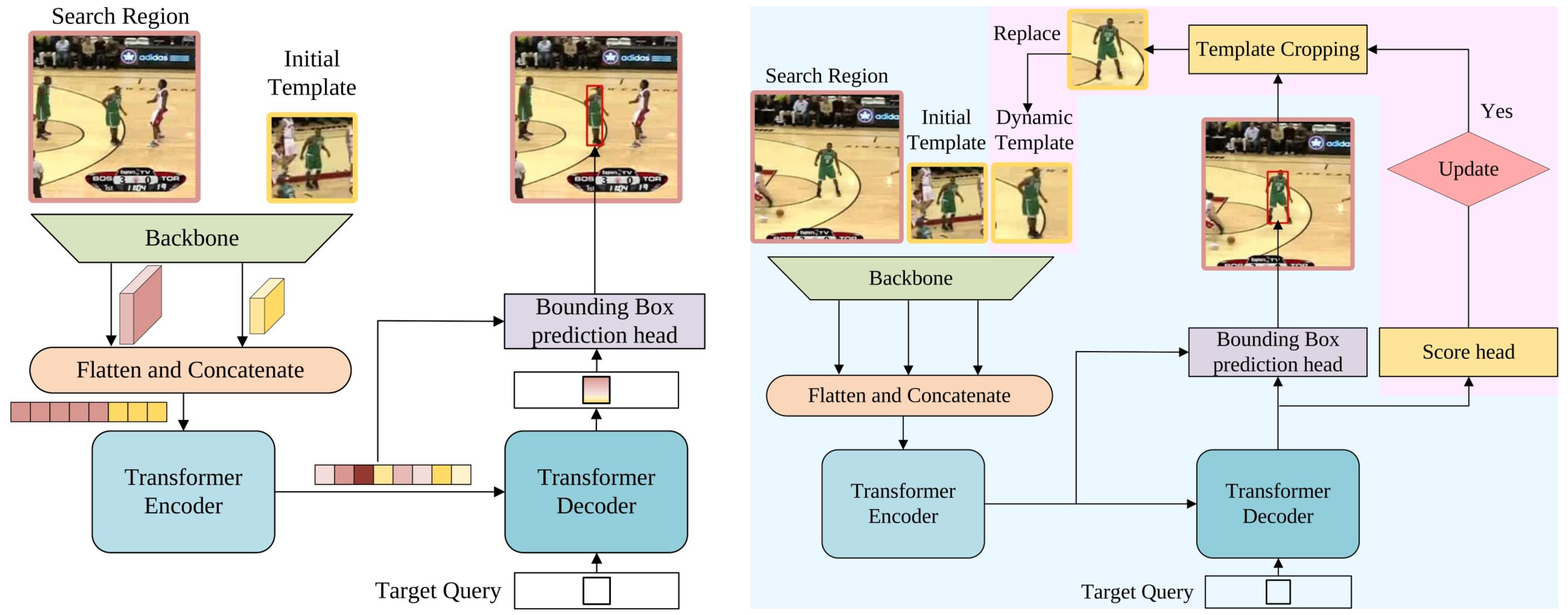
CV 论文《Learning Spatio-Temporal Transformer for Visual Tracking》笔记
Abstract
本文提出了一个基于 encoder-decoder transformer 架构的目标跟踪网络,其中 encoder 用于对目标对象和搜索区域的全局时间特征和空间特征关系进行建模,decoder 用于预测目标对象的位置。在预测阶段仅使用一个 FCN 用于预测 bounding box 的两个端点。整个过程是端到端的,效率和测试表现均达到 SOTA。
A Simple Baseline Based on Transformer
文章首先提出了一个仅考虑空间信息的 Baseline。
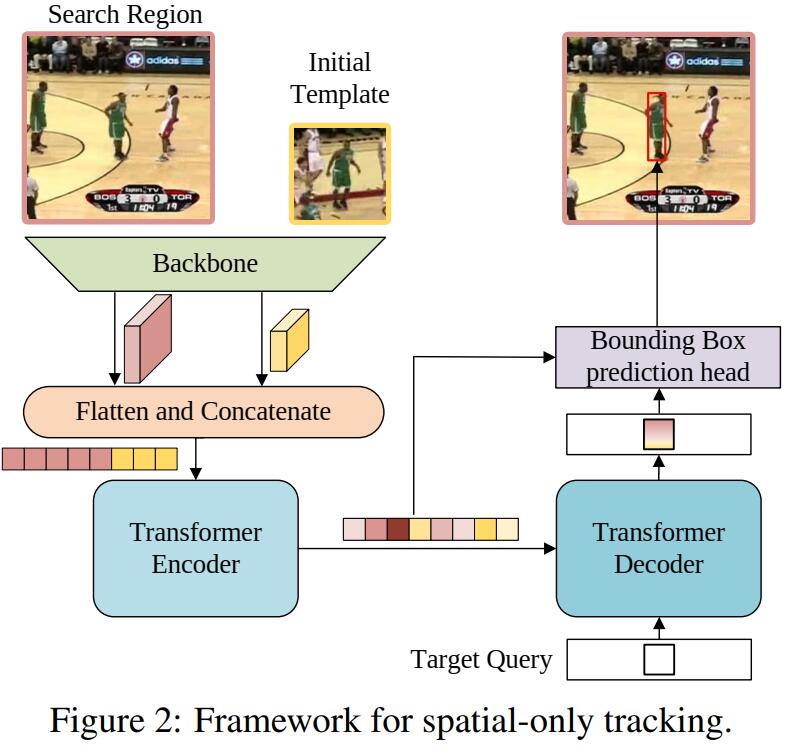
Backbone
使用 vanilla ResNet 作为 backbone 分别提取 search 和 template 的特征。输入 template 图像 $z\in \mathbb R ^{3\times H_z\times W_z}$ 和 search 图像 $x\in \mathbb R ^{3\times H_x\times W_x}$,经过 backbone 得到特征图 $f_z \in \mathbb R ^{C\times \frac{H_z}{s}\times \frac{W_z}{s}}$,$f_x \in \mathbb R ^{C\times \frac{H_x}{s}\times \frac{W_x}{s}}$。
Encoder
Adjust
得到特征图后通过一层网络将通道数 $C$ 降为 $d$,之后将后两维展开,得到 $f_z’ \in \mathbb R ^{d\times \frac{H_zW_z}{s^2}}$,$f_x’ \in \mathbb R ^{d\times \frac{H_xW_x}{s^2}}$;将 template 和 search 拼接,得到 $(d, \frac{H_zW_z}{s^2}+\frac{H_xW_x}{s^2})$ 的 token 序列。
原理分析
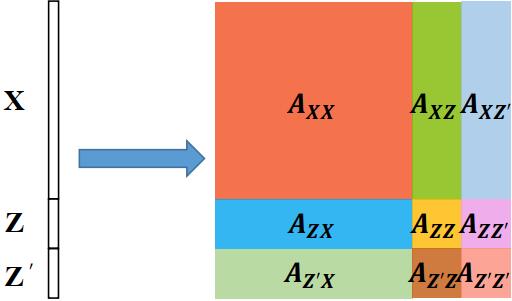
之后直接将向量序列嵌入位置信息后送入 encoder 层。可以通过一篇较新的论文 OSTrack 中的公式了解原理。根据 self-attention 的公式,有:
$$ A=\mathrm{Softmax} \left(\frac{QK^\top}{\sqrt{d_k}}\right)\cdot V = \mathrm{Softmax} \left(\frac{[Q_z;Q_x][K_z;K_x]^\top}{\sqrt{d_k}}\right)\cdot [V_z;V_x] $$
令 $W_{zx}= \mathrm{Softmax} \left( \frac{Q_z{K}_x^\top}{\sqrt{d_k}}\right)$,表示模板和搜索区域间相似度的度量,其余同理,将上式展开,有
$$ A=[W_{zz},W_{zx}; W_{xz},W_{xx}]\cdot (V_z;V_x)=[W_{zz}V_z+W_{zx}V_x;W_{xz}V_z+W_{xx}V_x] $$
其中 $W_{xz}V_z$ 对模板和搜索区域在空间上的联系进行建模,而 $W_{xx}V_x$ 基于图像全局提取了搜索区域的特征。因此特征提取和关系建模经由一次 self-attention 操作即可完成。
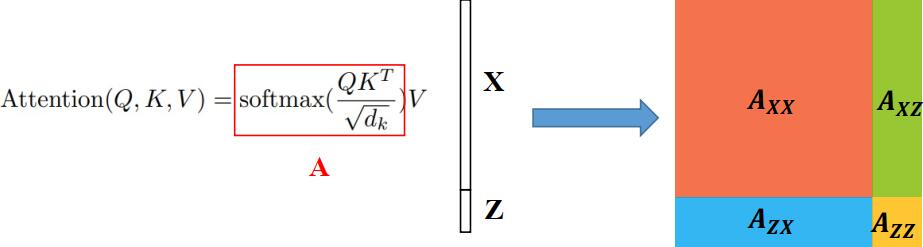
Decoder
将一个 target query 和 encoder 的输出送入 decoder,得到预测目标位置的一个一维向量,用于后续预测 bounding box。论文的 decoder 部分写的较为简略,说沿用了 DETR 的设计,只是将 query 个数减少为 1。
Head
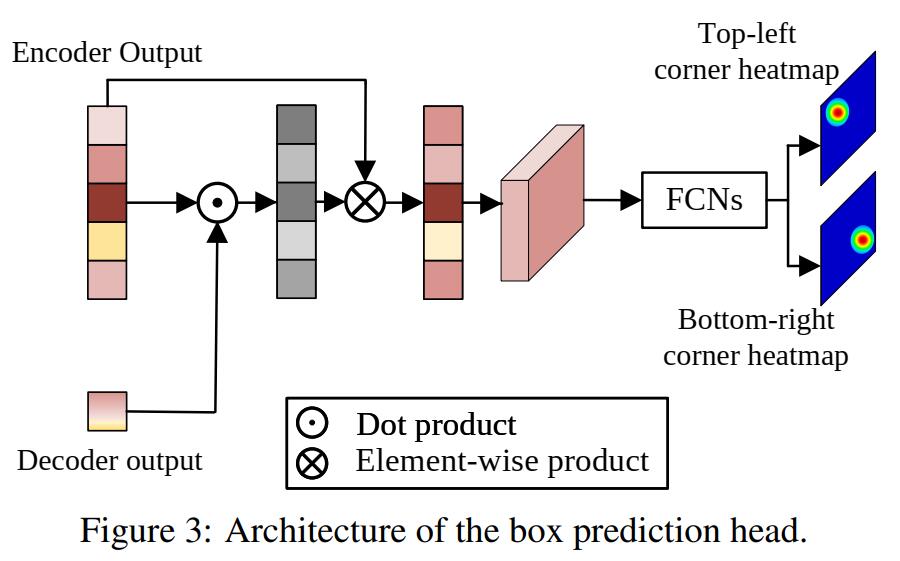
如图。首先将特征序列点乘 decoder 的输出得到模板和搜索区域的相似度向量,再与原特征序列相乘得到最终的特征序列。
作者在 STARK-ExtreMart 中分析得出该部分实际上仅等价于一个空间注意力模块,为了学习一个简单的空间注意力而使用 6 层 decoder 层是非必要的。实验也证明在 STARK-S 中去掉该部分对指标影响很小且优化了模型的性能和参数。
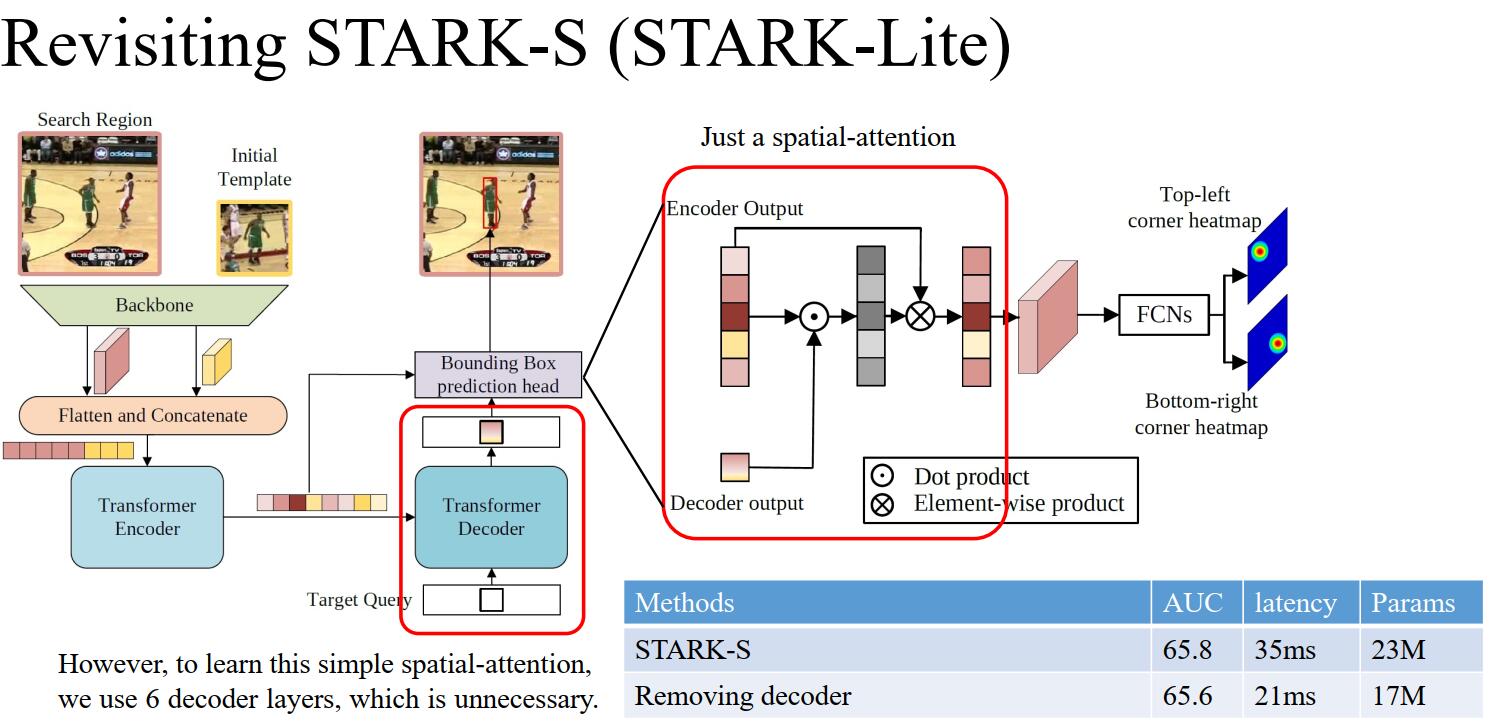
作者后来在模型的优化中就直接去掉了 decoder 模块。如下图是 STARK-Lighting(基于 STARK-S 进行优化后得到的高效模型)的网络结构:
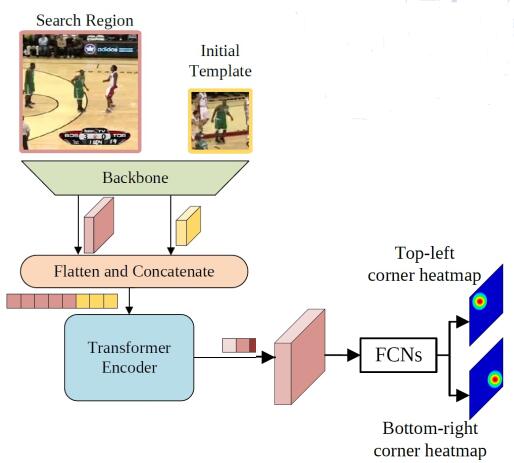
将特征序列展开成特征图 $f\in \mathbb R^{d\times \frac{H_s}{s}\times \frac{W_s}{s}}$,并送入 FCN,得到两张概率图 $P_{tl}(x,y), P_{br}(x,y)$,分别用于预测 bounding box 的左上角和右下角的坐标。将概率图的概率分布期望作为预测坐标,即
$$ (\hat{x_{tl}}, \hat{y_{tl}})=(\sum_{y=0}^H \sum_{x=0}^W x\cdot P_{tl}(x,y), \sum_{y=0}^H \sum_{x=0}^W y\cdot P_{tl}(x,y)) $$
(上述为左上,右下同理)
训练部分,损失函数仅包含 $l_1$ Loss 和 IoU Loss,不包含分类的损失:
$$ L=\lambda_{iou}L_{iou}(b_i,\hat{b_i})+\lambda_{L_1}L_1(b_i,\hat{b_i}) $$
Spatio-Temporal Transformer Tracking
基于上面的 baseline,考虑将时序信息也用于建模。这里主要通过适时加入当前帧的模板信息来实现。
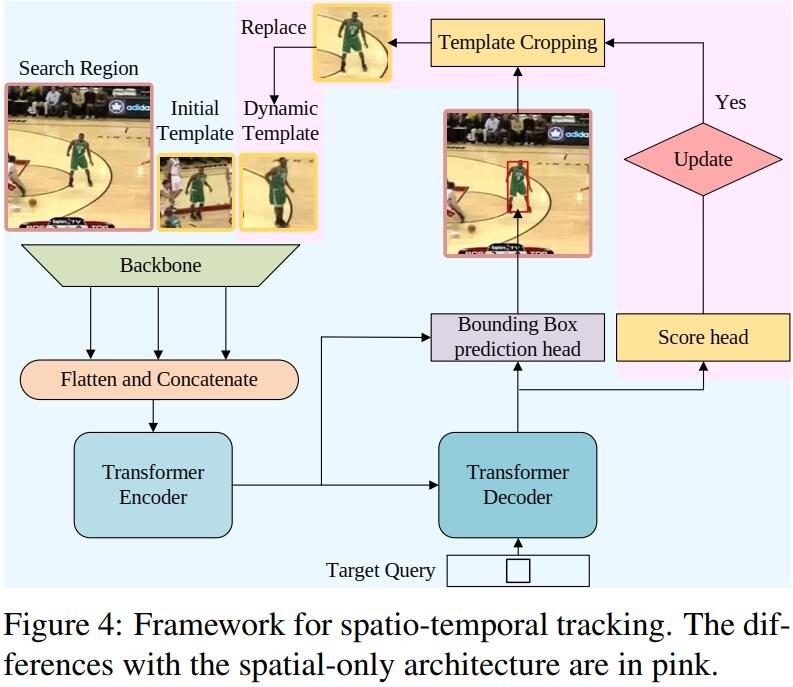
Input
与前面的 baseline 仅输入第一帧信息作为模板和当前帧作为搜索区域不同,新的方法从中间帧引入动态更新的模板作为附加输入,以提供额外的时序信息。
实现与前面一样,直接将三个输入拼接起来即可。
Head
目标跟踪时当目标被遮挡或丢失时不应更新动态模板。为简化问题,文章认为只要搜索区域包含目标就可以更新动态模板。所以文章添加了一个简单的 Score Head,包含三层感知机和一个 sigmoid 激活函数,若当前状态得分高于阈值则更新动态模板。
Train
在这里引入分类任务,但将定位和分类分开进行。将训练划分为两个阶段,第一阶段训练除了 Score Head 以外的部分,在保证搜索区域包含目标对象的前提下学习定位。在二阶段仅训练 Score Head,使用交叉熵作为 Loss:
$$ L_{ce}=y_i\log(P_i)+(1-y_i)\log(1-P_i) $$
其中 $y_i$ 是 groundtruth 标注,$P_i$ 是预测的置信度。在训练 Score Head 时冻结其余参数,防止影响定位部分。
初始时动态模板为第一帧的模板。当上一次更新距当前帧至少 $T_u$ 帧且 Score Head 给出的分数大于给定阈值,则从当前帧裁剪出新的动态模板作为输入。