《Cross-Modal Object Tracking ...》 论文阅读笔记
 xfarawayx
xfarawayx
目录
CV 论文《Cross-Modal Object Tracking: Modality-Aware Representations and A Unified Benchmark》笔记
背景
- 现有的目标跟踪方法大多基于 RGB 图像序列,然而这些方法在低光环境下存在局限性。现有的引入深度(RGB-D)或热成像(RGB-T)的方法由于需要对平台设计要求高,无法得到广泛应用。
- 许多监控摄像机包含近红外成像(NIR),在高光和低光环境下会分别切换为 RGB 成像和 NIR 成像(如题图)。两个模态特征差异大,为跟踪任务带来巨大挑战。本文主要尝试设计可嵌入式的网络解决减小两个模态数据的差异,并构建该类跨模态目标跟踪问题的 benchmark。
贡献点
- 提出一个新的具有挑战性和实践价值的任务:跨模态目标跟踪;
- 提出一个算法 MArMOT(Modality-Aware cross-Modal Object Tracking algorithm),用于减小两个模态图像之间的特征差异。该算法即插即用,可以方便嵌入各种主流跟踪算法框架。
- 提出了一个“三步训练法”有效训练跨模态的目标跟踪网络。
- 创建了一个跨模态目标跟踪问题的 benchmark 和对应的数据集,并通过实验证明上述方法有效。
MArMOT 模型
该模型结构如下:
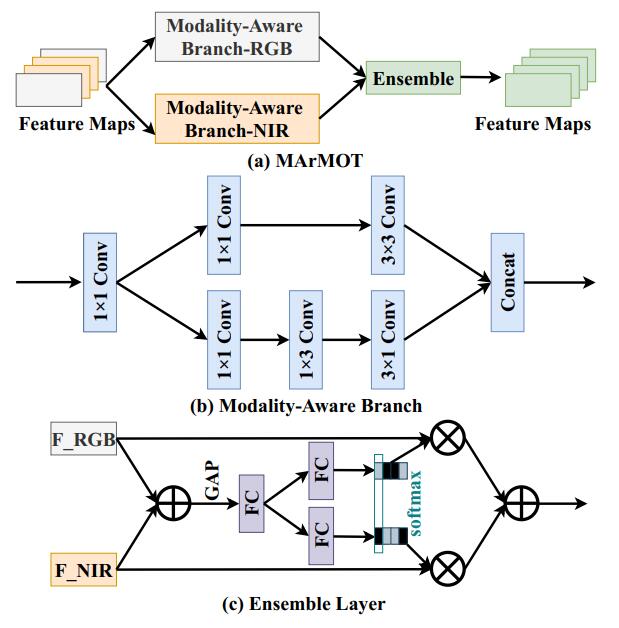
模型经过 backbone 后首先通过两个并行的分支,用于学习目标在不同模态下的模态独立特征(modality-specific representation)。每个分支采用类似 Inception Net 的结构。具体原理待学习。
之后使用 SKNet 融合两个特征。这里只用到 SKNet 后面的 Fuse 和 Select。
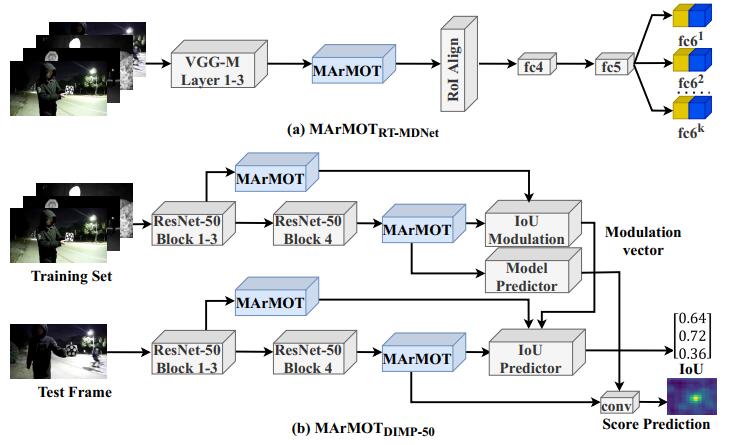
将该网络插入各主流目标检测框架后实验验证得到两个模态的特征差异确实减小。
“三步训练法”
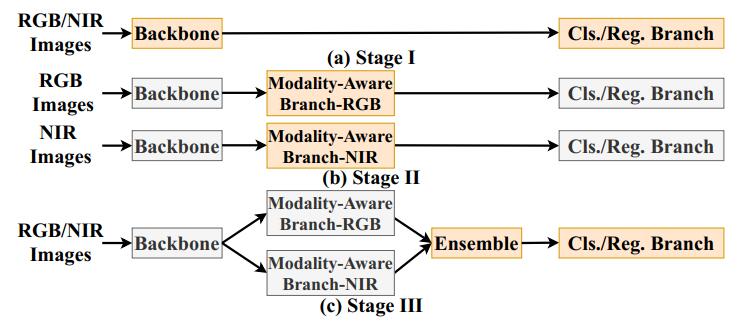
- 直接将 baseline 在数据集上微调。(此前 baseline 要在其他数据集上训练好)
- 分别将对应模态的图像送往对应的分支进行训练。
- 训练 SKNet 层并再次微调 baseline 模型。
CMOTB Benchmark
提供了一个名为 CMOTB 的跨模态目标识别数据集。此部分暂略。
实验
待填坑 QwQ